A data estate can be various and complex. For every application you have in production, you have many copies of that application running in lower environments. And not only do you have numerous lower environments, but the data needs of each environment can be notably different.
Consider the following example from a Delphix customer (before they had Delphix):
Acme Finance has three major applications that are interdependent: Asset Management, Wealth Management, and Investment Banking. Each of these applications use a different RDBMS, as well (Oracle, MSSQL, and ASE).
Acme Finance has the following environments:
- Dev - an insane amount of copies of each application using synthetic and subsetted data sets.
- Test - many different levels of testing, each with different testing needs that vary greatly in complexity. Functional can perhaps be performed in isolation on subsetted data, but integration and system testing require all the application datasets to be in sync and have referential integrity. The size of the data for these environments limits the amount of parallel testing environments they can have, and the complexity of coordinating data refreshes across three different database technolgies and teams severly limits the frequency that the testing environments can be provisioned with fresh non-polluted data. Data-related defects commonly make it to production.
- Perf - One environment. Uses full production datasets. The size and complexity create the same constraints experinced in system and integration testing. Perf typically gets one run in a testing cycle to identify any potential performance tweaks.
- Staging/UAT - One environment. Uses full production datasets. The size and complexity create the same constraints experinced in system and integration testing. Users commonly encounter errors due to data pollution.
- There are also BreakFix, Analytics, and AI/ML environments.
All of these discrete datasets throughout their enterprise, and to add insult to injury, they don’t mask because it is too hard to accomplish!
By leveraging Delphix, you can bring data into your delivery pipeline and automate the way you protect, build, and deliver it as easy as you do code.
In our example, we show the Delphix Dynamic Data Platform integrated with Jenkins to:
- Get the latest data from production
- Create a masked copy of production data so it is clean for use in lower environments
- Reset/drop production usernames and passwords
- Create parallel data preparation environments
- Execute subset jobs against data preparation environments**
- Bookmark the data in those environments so that the data is now available via automation and self-Service
** Subsetting is simulated in this example. Delphix does not subset data, but many of our customers use their existing subsetting products to perform this functionality in the manner described above.
While we wait for the remainder of the Data Pipeline build job to finish, we will go over some of the details of what is actually happening.
The format of this scene will differ a little bit, as you will execute steps as we go along and explain some things.
We use myriad techniques to accomplish the data automation in the Pipeline for demonstration and educational purposes. In practice, the user could leverage any method they prefer.
YOUR STEPS FOR THIS SCENE:
- Click the
Jenkinsbookmark. - Click on the
Data Pipeline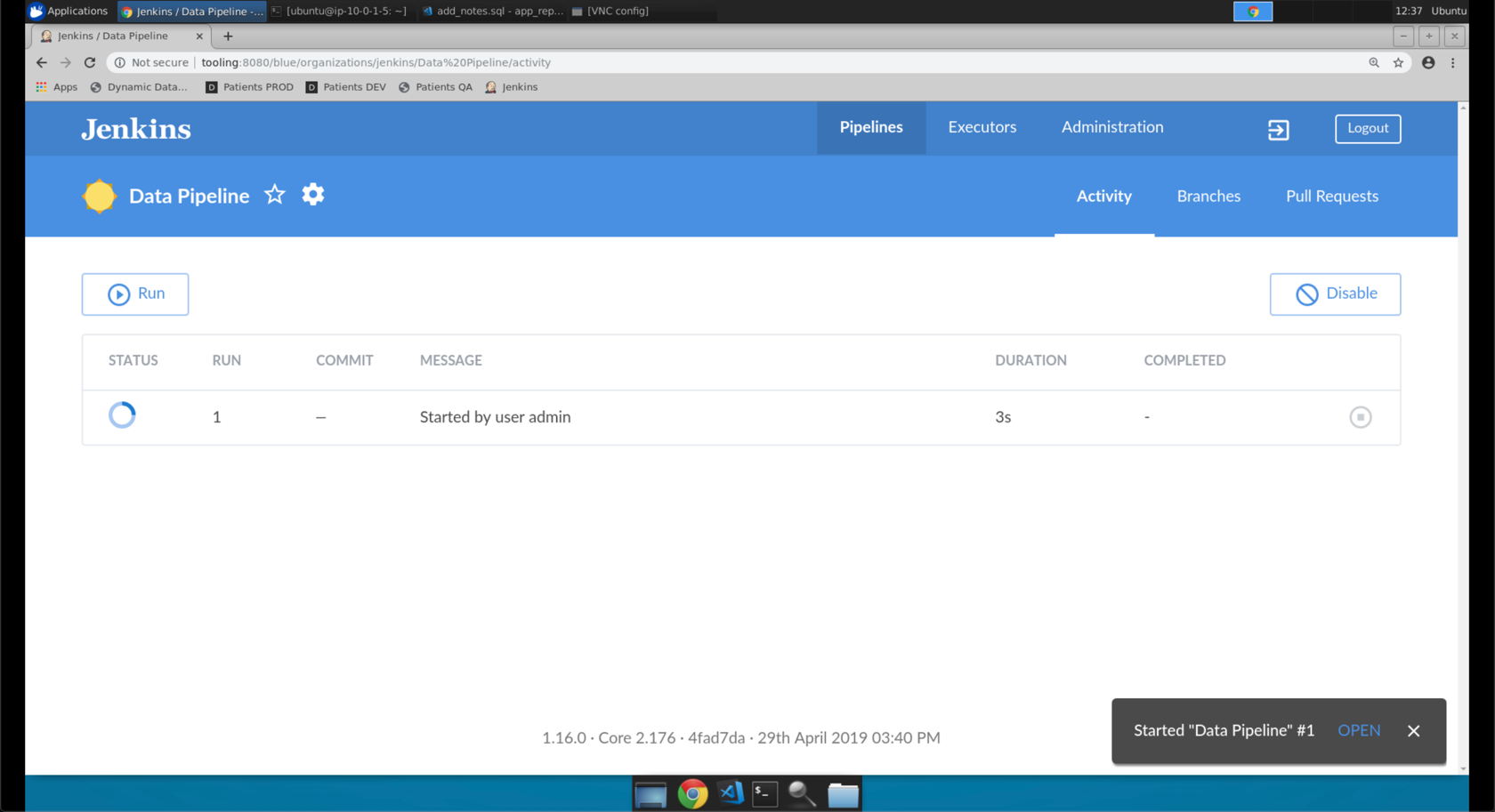
- Click on the job at the top of the list.
This screen shows us the various stages of the
Data Pipeline. TheData Pipelineis a declarative Jenkins Pipeline. The Pipeline is defined by a file (Jenkinsfile) that is stored with our application code in version control.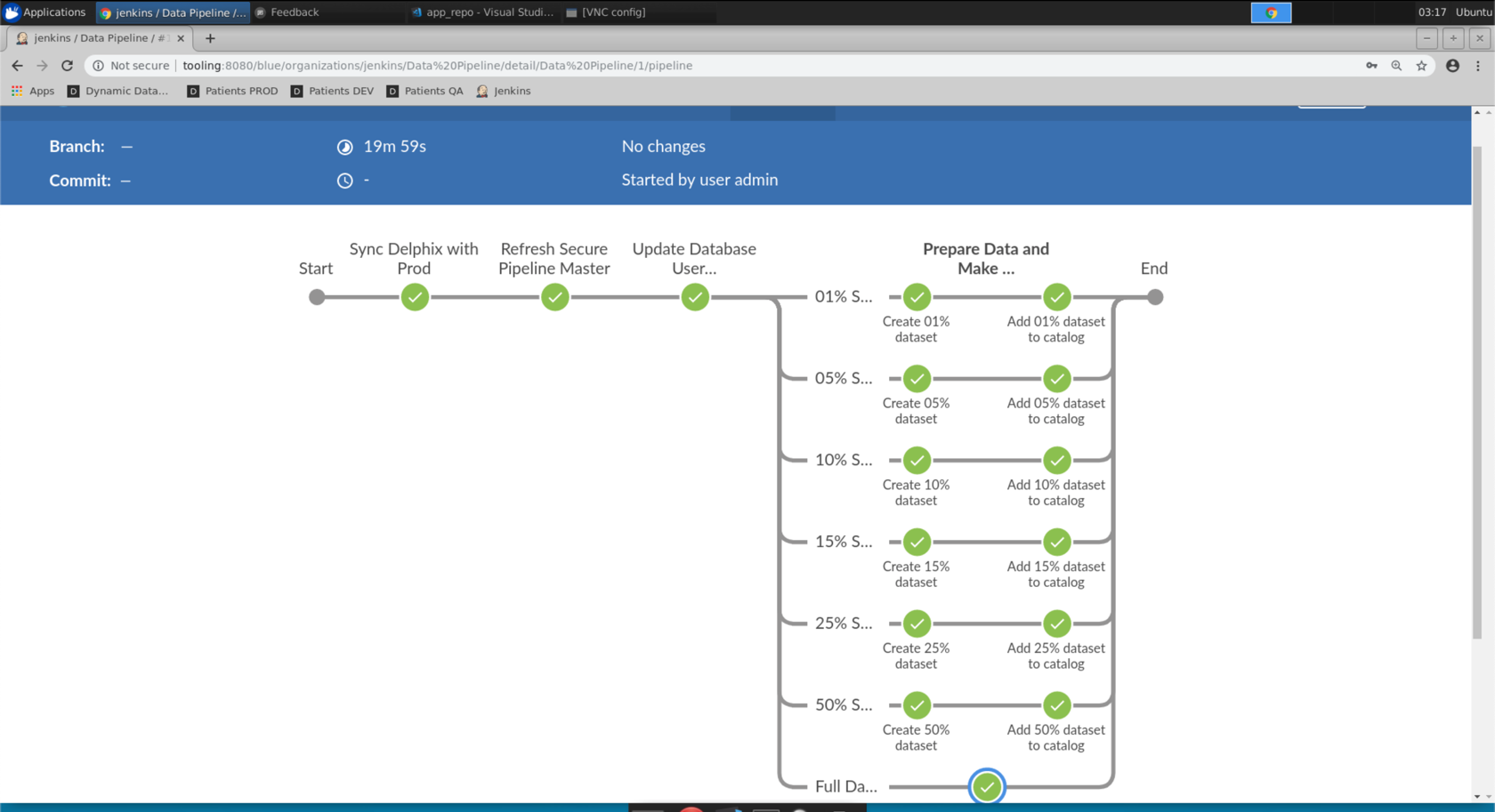
- OPTIONAL: The relevant contents of the
Jenkinsfilehave been included in images on this page for convenience, but you can clone the actual file in your environment by executingcd ~/git git clone git@tooling:/var/lib/jenkins/data-pipeline.git -
Let’s inspect the
Jenkinsfile.In the image below, several sections of the Jenkinsfile have been collapsed for clarity.
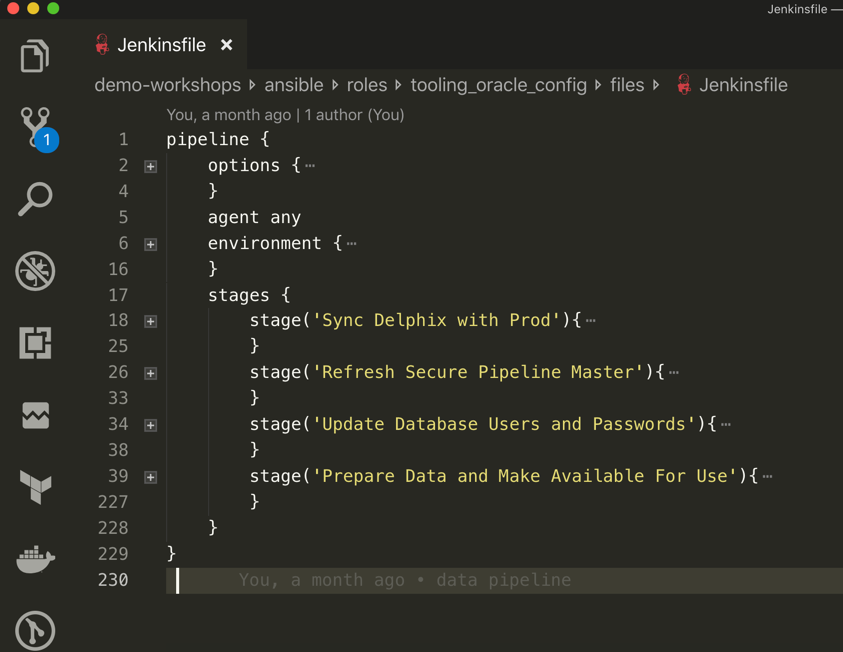
The main sections of the Jenkinsfile include:
- environment - This section establishes environment variables that are set and/or read during the exection of the Pipeline.
- stage(<name>) - Each of these correspond to named stages you saw in the job view in your web browser
The stages of the Jenkinsfile:
- Sync Delphix with Prod - This stage exists for aesthetics of the pipeline to better show the flow. Syncing the production data with Delphix is executed in the next stage in combination with the refresh.
- Refresh Secure Pipeline Master - Jenkins executes a Golang binary (
snap_prod_refresh_mm) which sends REST calls to the DDDP to:- Snapshot the production database
- Refresh the
Patients Masked Masterdata pod with the latest data from production and mask it according to the defined policy.
- Update Database Users and Passwords - This phase is a placeholder for where you could specify calls to any external tools you may have to reset application and database usernames and passwords.
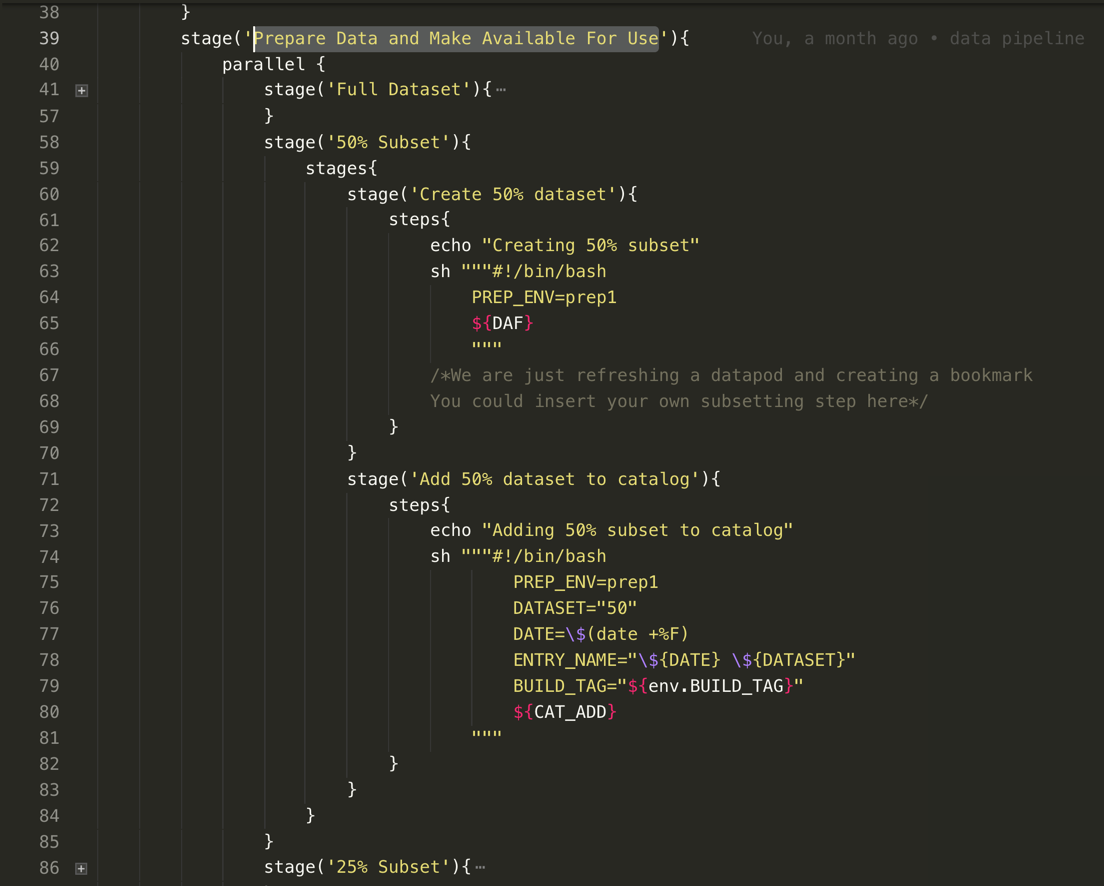
- Prepare Data and Make Available For Use - This stage executes six near identical parallel stages.
One stage is expanded in the image below:
- Jenkins executes a kotlin binary (Delphix Automation Framework (DAF)) which sends REST calls to the DDDP to spinup a data pod.
- Jenkins executes a subsetting job (simulated)
- Jenkins executes a python script (dx_jetstream_container.py) which sends REST calls to Delphix to bookmark the
Patients Masked Masterand to make that bookmark available to Delphix Self Service.
Now, feel free to explore around until your Data Pipeline job completes.
Just be sure to not click Save or Apply, and you should be able to stay clear of doing any real damage.
Once the Data Pipeline job has completed, you are ready for the next scene.